|
|
K. F. Meis (© 2002-2021)
|
Anmerkung 3: Grundsätzliches zur Protein-Codierung in der DNSDie folgenden Ausführungen sind nur als Hintergrundinformation gedacht: Die DNS besteht aus folgenden Nukleotiden:
Dabei gehören A und T zusammen, sowie G und C. Die Anzahl aller möglichen Kombinationen beträgt 4 (A-T, T-A, G-C und C-G). Mit den vier Buchstaben lassen sich somit 4 Werte darstellen (entspricht 2 Bit). Drei dieser Kombinationen (Triplett genannt) ergeben ein 'Wort'. Die Anzahl der dadurch möglichen unterschiedlichen Worte beträgt 64 (4 x 4 x 4 = 64, das entspricht 6 Bit). Es stehen somit 64 mögliche 'Worte' zur Verfügung. Da aber nur 20 verschiedene Aminosäuren verwendet werden, stehen für eine Aminosäure meist mehrere Tripletts zur Verfügung. 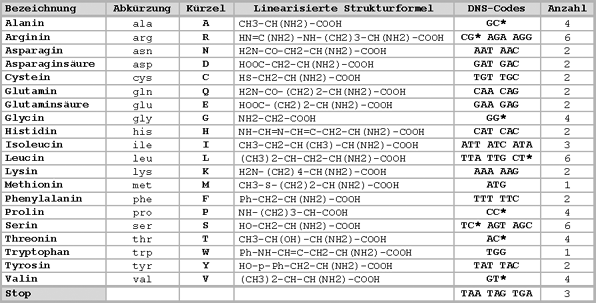 Da 4 x 4 aber nur 16 ergibt, würde ein 'Wort' aus zwei Kombinationen nicht ausreichen, um 20 Aminosäuren zu codieren. Jede Aminosäure lässt sich also mit unterschiedlich vielen Triplets codieren. Manche Aminosäuren lassen sich nur mit einem Triplet codieren (Methionin und Tryptophan), andere lassen sich mit 6 verschiedenen Triplets codieren (Arginin, Leucin und Serin). |
|
Last update: 08.03.2021 |

